
Extraction Formula Examples
Learn how to write extraction formulas by following along with these examples.
Writing an extraction formula requires a lot of decision-making and forethought. In this topic, we'll walk you through a series of different examples that each become more complex or build on the previous example. For more information about functions you can use in a Visier extraction formula, see Visier Extraction Language (VEL).
Local assignments
You can use local assignments in your formulas to simplify your expressions and avoid repeating the same function logic. A local assignment gives a name to an expression, which you can reference elsewhere in the formula. This makes your formulas cleaner and easier to maintain, while still behaving as if the original expression were used. Local assignments can reference any other assignments defined earlier in the formula, but once a name has been assigned, it cannot be redefined later.
Syntax
name := expressionExamples
In this example the expression column("Name") is replaced by the local assignment name col.
col := column("Name")Local assignment will hide functions with the same name, preventing future library functions from breaking existing formulas. For example, if you name an assignment sum := a + b + c, and a library function sum is added later, your formula will still work as expected.
While it is recommended to put each assignment on a separate line, it's not required. In this example, the assignment shares a line with the formula body. To prevent the formula from being misread as part of the assignment, you can use a semicolon. Semicolons help clarify the end of assignments and can be used anywhere, including multi-line or long single-line formulas. Below, x := 1; ends the assignment, avoiding confusion with x := 1 - 2.
x := 1; -2Combine column values
Write an extraction formula to combine values from two or more columns.
Scenario
You want to display the first name, last name, and employee ID as a single property so you can identify employee's by their full name and ID, making it easier to search for them quickly in Detailed View.
In your employee file, the employee ID (EmployeeID), first name (FirstName), and last name (LastName) are stored in separate columns.
|
EmployeeID |
FirstName |
LastName |
|---|---|---|
|
Employee-4831 |
Johnson |
Mccrary |
|
Employee-201 |
Lemarcus |
Billings |
|
Employee-204 |
Shanique |
Jones |
|
Employee-339 |
|
Sanchez |
|
Employee-494 |
Revel |
Parsons |
In this example, you want the property to have the following structure, with the employee ID enclosed in parentheses: FirstName LastName (EmployeeID). For example, Taylor Kelce (Employee-1387).
Formula breakdown
You can solve this by writing an extraction formula that combines the values from the EmployeeID, FirstName, and LastName columns.
Syntax
input_string1 + input_string2
- input_string The first and second strings you want to join. It can be the name of the column or a string enclosed in double quotation marks. The data type of the column cannot be a number. required
- + Operator that concatenates two or more strings together. required
Example
column("FirstName")
+ " "
+ column("LastName")
+ " ("
+ column("EmployeeID")
+ ")"- The column function returns the column values from the data source.
- The pair of double quotation marks separated by a space character " " is used to insert a space between the first name and last name.
- The extra pair of parentheses in the " (" column("EmployeeID) + ")" expression is needed to display the employee ID in parentheses.
Result
You will get the following results when the extraction formula is applied:
|
EmployeeID |
FirstName |
LastName |
Extracted Property Value |
|---|---|---|---|
|
Employee-4831 |
Johnson |
Mccrary |
Johnson Mccrary (Employee-4831) |
|
Employee-201 |
Lemarcus |
Billings |
Lemarcus Billings (Employee-201) |
|
Employee-204 |
Shanique |
Jones |
Shanique Jones (Employee-204) |
|
Employee-339 |
|
Sanchez |
Sanchez (Employee-339) |
|
Employee-494 |
Revel |
Parsons |
Revel Parsons (Employee-494) |
Employee-339 is missing a first name, so the extracted property value starts with an extra space. You can apply additional logic to remove the space or insert additional information to let users know that not all employees have first names. Let's adjust our extraction rule and add the stringReplace function to remove the space.
Formula breakdown
The stringReplace function replaces occurrences of a specified substring within a string with another substring. In this example, it is used to remove the leading space from Employee-339's name.
Syntax
stringReplace(input_string, start_index, num_of_characters, replacement_string, [DefaultValue])
- input_string The source string or column that needs to be replaced. required
- start_index A zero-based index indicating the start of the replacement in the source string. required
- num_of_characters Indicates the number of characters in the source string that will be replaced.
- replacement_string The new string that takes the place of another.
- [DefaultValue] The value that will be used if no matching condition is found.
Example: Remove space
concanated_string := (column("FirstName")
+ " "
+ column("LastName")
+ " ("
+ column("EmployeeID")
+ ")"
)
stringReplace(concanated_string, 0, 2, " ")Result
You will get the following results when the extraction formula is applied:
|
EmployeeID |
FirstName |
LastName |
Extracted Property Value |
|---|---|---|---|
|
Employee-4831 |
Johnson |
Mccrary |
Johnson Mccrary (Employee-4831) |
|
Employee-201 |
Lemarcus |
Billings |
Lemarcus Billings (Employee-201) |
|
Employee-204 |
Shanique |
Jones |
Shanique Jones (Employee-204) |
|
Employee-339 |
|
Sanchez |
Sanchez (Employee-339) |
|
Employee-494 |
Revel |
Parsons |
Revel Parsons (Employee-494) |
Example: Remove space with additional information
concanated_string := (column("FirstName")
+ " "
+ column("LastName")
+ " ("
+ column("EmployeeID")
+ ")"
)
stringReplace(concanated_string, 0, 2, "<Unknown> ")- When conditions are met, the space will be replaced with the string: Unknown to let users know that an employee does not have a first name.
Result
You will get the following results when the extraction formula is applied:
|
EmployeeID |
FirstName |
LastName |
Extracted Property Value |
|---|---|---|---|
|
Employee-4831 |
Johnson |
Mccrary |
Johnson Mccrary (Employee-4831) |
|
Employee-201 |
Lemarcus |
Billings |
Lemarcus Billings (Employee-201) |
|
Employee-204 |
Shanique |
Jones |
Shanique Jones (Employee-204) |
|
Employee-339 |
|
Sanchez |
<Unknown> Sanchez (Employee-339) |
|
Employee-494 |
Revel |
Parsons |
Revel Parsons (Employee-494) |
Derive values using existing columns
Write an extraction formula to derive an attribute value from existing columns.
Scenario
Your employee file contains the country where each employee is located, but not their currency code. You need a way to automatically assign the correct currency code based on their country. For example, if an employee lives in the United States, their currency code should automatically be USD.
Formula breakdown
You can solve this by writing an extraction formula using the replace function that derives the currency code based on the Country column.
Syntax
replace(input_string, {from_value -> to_value [, _]}, [DefaultValue])
- input_string The source string or column that needs to be replaced. required
- from_value The string that needs to be replaced. required
- to_value The replaced value. required
- [, _] The list of mapping strings.
- [DefaultValue] The value that will be used if no match is found in the mapping list. You can define it with a string, such as USD, or Not Defined.
Example
In this option, you add the column that is used for matching, then define the rule for the match, using the -> operator to assign the values.
replace(column("Country"), {
"United States" -> "USD",
"US" -> "USD",
"Canada" -> "CAD",
"CAN" -> "CAD",
"United Kingdom" -> "GBP",
"UK" -> "GBP",
"France" -> "EUR",
"Germany" -> "EUR”
})Result
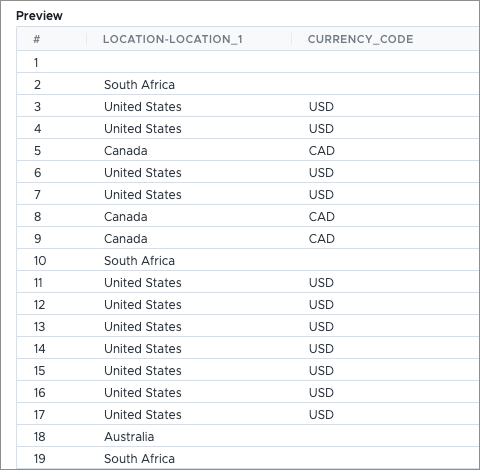
You did not set a default value in this formula, so if there is no match the derived value will be blank.
Example: Use the replace function with the identity function
If you don't want to set a default value or have blanks, you can use the identity function to keep the original value when no match is found in the replace condition.
replace(column("Country"), {
"United States" -> "USD",
"US" -> "USD",
"Canada" -> "CAD",
"CAN" -> "CAD",
"United Kingdom" -> "GBP",
"UK" -> "GBP",
"France" -> "EUR",
"Germany" -> "EUR"
}, identity)The identity function returns the same value that it receives as an input. In this example, we've defined a replace condition for only a few countries. Instead of leaving the derived currency code blank, we want to retain the value from the original column when the replace conditions are not met.
Result
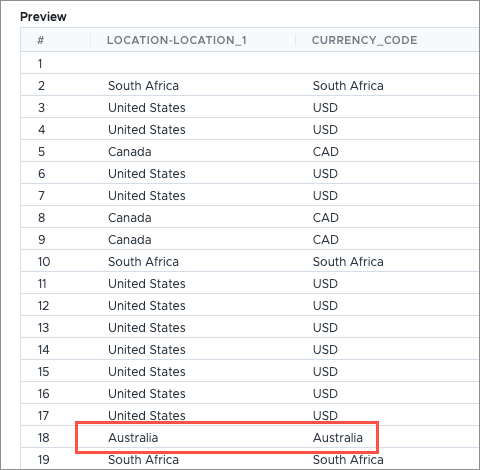
The value from the original column is passed through as the currency code for countries that were not defined in the replace condition, such as South Africa and Australia.
Example: Replace function with local assignment
You can use local assignment to temporarily store a value in a variable, then call it later in the formula.
Location_CurrencyCode := {
"United States" -> "USD",
"US" -> "USD",
"Canada" -> "CAD",
"CAN" -> "CAD",
"United Kingdom" -> "GBP",
"UK" -> "GBP",
"France" -> "EUR",
"Germany" -> "EUR"
}
replace(column("Country"), Location_CurrencyCode)In this example, the variable is named Location_CurrencyCode and is later referenced in the replace function.
Extract a substring from a column
Write an extraction formula to get portions of a string column.
Scenario
You need to populate the Location dimension, but the information is stored in the Address column, which includes the city, state, region, and country.
|
Address |
|---|
|
151 Giovanny Haven, Apt. 765, 57191, North Maximo, Washington, United States |
|
392 Deckow Oval, Apt. 208, 67726, East Mariloumouth, California, United States |
|
66318 Schiller Wall, Suite 607, C8S 8X1, East Delaney, Alberta, Canada |
|
Mettlacher Str. 88c, Zimmer 265, 42343, Blumescheid, Sachsen-Anhalt, Germany |
|
5 Boulevard de Vaugirard, Apt. 533, 40379, Paris, Pays de la Loire, France |
|
368 Ebert Way, Suite 364, 6385, Krisfort, New South Wales, Australia |
Formula breakdown
To populate the Location dimension, you can write an extraction formula that extracts parts of the Address column. You want to start by looking for patterns in the strings you want to extract information from. When there is a pattern, you can use the indexOf function to get the string you want to isolate and use the functions StringLeft, StringRight, stringDropLeft, and stringDropRight, to include or remove characters from the string.
Example: Extract the substring for country
Extracting the substring for country is the easiest because it is at the end of the address. Use the indexOf function to find the last comma in the address, and then drop all strings before the last comma. To make these examples easier to understand, we will be using variables to store the values.
address := column(Address)
lastIndexOfComma := lastIndexOf(address, ", ")
stringDropLeft(address, lastIndexOfComma)- address := column(Address) Used to define the variable for the column that contains the data we are trying to transform. The variable reduces the amount of times we need to write the full name of the column. It will also save time if we need to switch to a different column, you can adjust the formula for the variable just once.
If you apply the formula to 151 Giovanny Haven, Apt. 765, 57191, North Maximo, Washington, United States, you would extract the following substring: , United States. This is because the index is pointing to the last comma. You need to add 2 to the index so it drops the comma and space.
address := column(Address)
lastIndexOfComma := lastIndexOf(address, ", ") + 2
stringDropLeft(address, lastIndexOfComma)Example: Extract the substring for region
Region is not provided in the address, but you can use the country information to derive the employee's region. Using the previous scenario, we will calculate values using existing columns.
address := column(Address)
lastIndexOfComma := lastIndexOf(address, ", ") + 2
country := stringDropLeft(address, lastIndexOfComma)
replace(country, {
"United States" -> "North America",
"Canada" -> "North America",
"United Kingdom" -> "EMEA",
"France" -> "EMEA",
"Germany" -> "EMEA",
"Australia" -> "APAC"
})Example: Extract the substring for state
State is always on the left of the country in the address. Use the indexOf function to find country in the address, and then drop all strings before the country.
address := column(Address)
lastIndexOfComma := lastIndexOf(address, ", ")
dropCountry := stringLeft(address, lastIndexOfComma)
secondLastIndexOfComma := lastIndexOf(dropCountry, ", ") + 2
stringDropLeft(dropCountry, secondLastIndexOfComma)Using 151 Giovanny Haven, Apt. 765, 57191, North Maximo, Washington, United States as an example.
- lastIndexOfComma := lastIndexOf(address, ", ") Finds the position where the last ", " is found. In this example, it returns the position 61.
- dropCountry := stringLeft(address, lastIndexOfComma) Using the index found in the previous line, the stringLeft function is used to drop everything from the left side, starting from position 61. In this example, United States is dropped and 151 Giovanny Haven, Apt. 765, 57191, North Maximo, Washington is returned.
- secondLastIndexOfComma := lastIndexOf(dropCountry, ", ") + 2 Without + 2, , Washington is returned. The expression is added to move the index after the comma and space.
- stringDropLeft(dropCountry, secondLastIndexOfComma) Drops the extra comma and space that precede the state, returning Washington.
Example: Extract the substring for city
We can use the same logic to isolate city by dropping all strings to the left of the city in the address.
address := column(Address)
lastIndexOfComma := lastIndexOf(address, ", ")
dropCountry := stringLeft(address, lastIndexOfComma)
secondLastIndexOfComma := lastIndexOf(dropCountry, ", ")
dropState := stringLeft(address, secondLastIndexOfComma)
thirdLastIndexOfComma := lastIndexOf(dropState, ", ") + 2
stringDropLeft(dropState, thirdLastIndexOfComma)Retrieve values from a JSON column
Write an extraction formula to return the value from a simple, JSON column for a dimension. This example shows a simple JSON structure with a flat structure and key-value pairs.
Scenario
Employee contact information is extracted from the source system as JSON in a single column. You want to get the employee's email from the Contact Details column.
{
"home phone":"(307) 555-0100",
"cellphone”:"(308) 267-2479",
"email":"johnson.mccrary.0264@gmail.com"
}{
"home phone":"",
"cellphone":"(775) 246-1601",
"email":"l_billings_5964@gmail.com",
"mailling address": "701 Crona Green, Suite 566, S8V 7S5, Port Abdul, Northwest Territories, Canada"
}Formula breakdown
You can solve this by writing an extraction formula using the jsonColumn function to return the email value.
Example
jsonColumn("ContactDetails", "email")
Retrieve values from a complex JSON column
Write an extraction formula to return multiple values from a complex, JSON column for a dimension. This example shows a complex JSON structure with a hierarchical structure and nested objects and arrays.
Scenario
Employee contact information is extracted from the source system as JSON in a single column. You want to get the employee's email and phone number from the ContactDetails column. There are two phone numbers, so you will need to add logic to determine which value is extracted.
{
"firstName": "Johnson",
"lastName": "Mccrary",
"age": 26,
"address": {
"streetAddress": "",
"city": "",
"postalCode": ""
},
"phoneNumbers": [
{
"type": "home",
"number": "(307) 555-0100"
},
{
"type": "cell",
"number": "(308) 267-2479"
}
],
"email": "johnson.mccrary.0264@gmail.com"
}{
"firstName": "Lemarcus",
"lastName": "Billings",
"age": 30,
"address": {
"streetAddress": "701 Crona Green, Suite 566",
"city": "Port Abdul",
"postalCode": "S8V 7S5"
},
"phoneNumbers": [
{
"type": "home",
"number": ""
},
{
"type": "cell",
"number": "(775) 246-1601"
}
],
"email": "l_billings_5964@gmail.com"
}Formula breakdown
You can solve this by writing an extraction formula using the jsonPathColumn function to return the email and phone number values. This function is specific for a string-type json field and will not extract the proper value if used on doubles, integers, or dates. The jsonPathColumn is resource-intensive and may impact performance, so please use it cautiously.
Use this online evaluator tool to test your extraction rule for json.
Syntax
jsonPathColumn(input_string, json_path)
- input_string The string or column name where the JSON is stored in the file. required
- json_path Lets you pinpoint and extract specific pieces of data from JSON using expressions to navigate through its structure. It is always prefixed with the dollar sign ($) and follows the syntax: jsonPath: $.<parentTag>[?(@.<childTag1> == ‘<value>’)].<childTag2> required
- $ The root of the JSON document. It acts as a starting point from which the query is evaluated.
- <parentTag> The direct child of the root element. It is the key or label that contains child tags within a nested structure. For example, phoneNumbers.
- [?()]: A filter operation that allows us to apply conditions to narrow down the data. This expression filters the results based on a specific condition inside the parentheses.
- @: The reference to the current element in the iteration. Together with childTag1, @.<type>, looks for all occurrence of type.
- == '<value>': The value of the childTag1. For example, home.
- .<childTag2>: Accesses a nested child tag of the current element after the filter condition is applied.
Example: Extract the email
jsonPathColumn("ContactDetails", "$.email")Example: Extract the phone number
In this example, only the cellphone number is extracted. If it is not provided, the home phone number is extracted instead.
homePhone := jsonPathColumn("ContactDetails", "$.phoneNumbers[?(@.type == 'home')].number”)
cellPhone := jsonPathColumn("ContactDetails", "$.phoneNumbers[?(@.type == cell)].number”)
if (cellPhone != "")
cellPhone
else if (homePhone != "")
homePhone
else
noneConvert an epoch timestamp
Write an extraction formula to convert an epoch timestamp into a date formatted as yyyy-MM-dd.
Scenario
The date column in the extracted data is an epoch timestamp. You need to convert it to the yyyy-MM-dd date format before loading it into Visier. In this example, the epoch timestamps are contained in the SystemModstamp column.
|
EmployeeID |
FirstName |
LastName |
SystemModstamp |
|---|---|---|---|
|
Employee-4831 |
Johnson |
Mccrary |
1729285179000 |
Formula breakdown
You can solve this by writing an extraction formula using the utcEpochToDate function.
Syntax
utcEpochToDate(<columnName>)
- <columnName> = The name of the column that contains the epoch timestamps. Ensure the column's data type is TEXT. required
Example
utcEpochToDate(column(“SystemModstamp”))Result
|
EmployeeID |
FirstName |
LastName |
SystemModstamp |
Extracted Date |
|---|---|---|---|---|
|
Employee-4831 |
Johnson |
Mccrary |
1729285179000 |
2024-10-18 20:59:39.000 |