
Vee Architecture, Privacy, and Security
Learn more about the data flow architecture and information security for Vee.
Overview
Vee doesn’t speak the same language that a person speaks so it needs some assistance to ensure it understands the natural language input.
Architecture and data flow
Vee uses large language models for the advanced translation of natural language into query language and generating summaries of text. Customer data is not used for training purposes and no prompt submissions are retained.
Ask Vee 2.0 a question
Vee partners with third-party large language models (LLMs) to understand user questions and provide clear, narrative responses based on retrieved data. The following diagram illustrates the architecture and data flow when a user asks Vee a question.
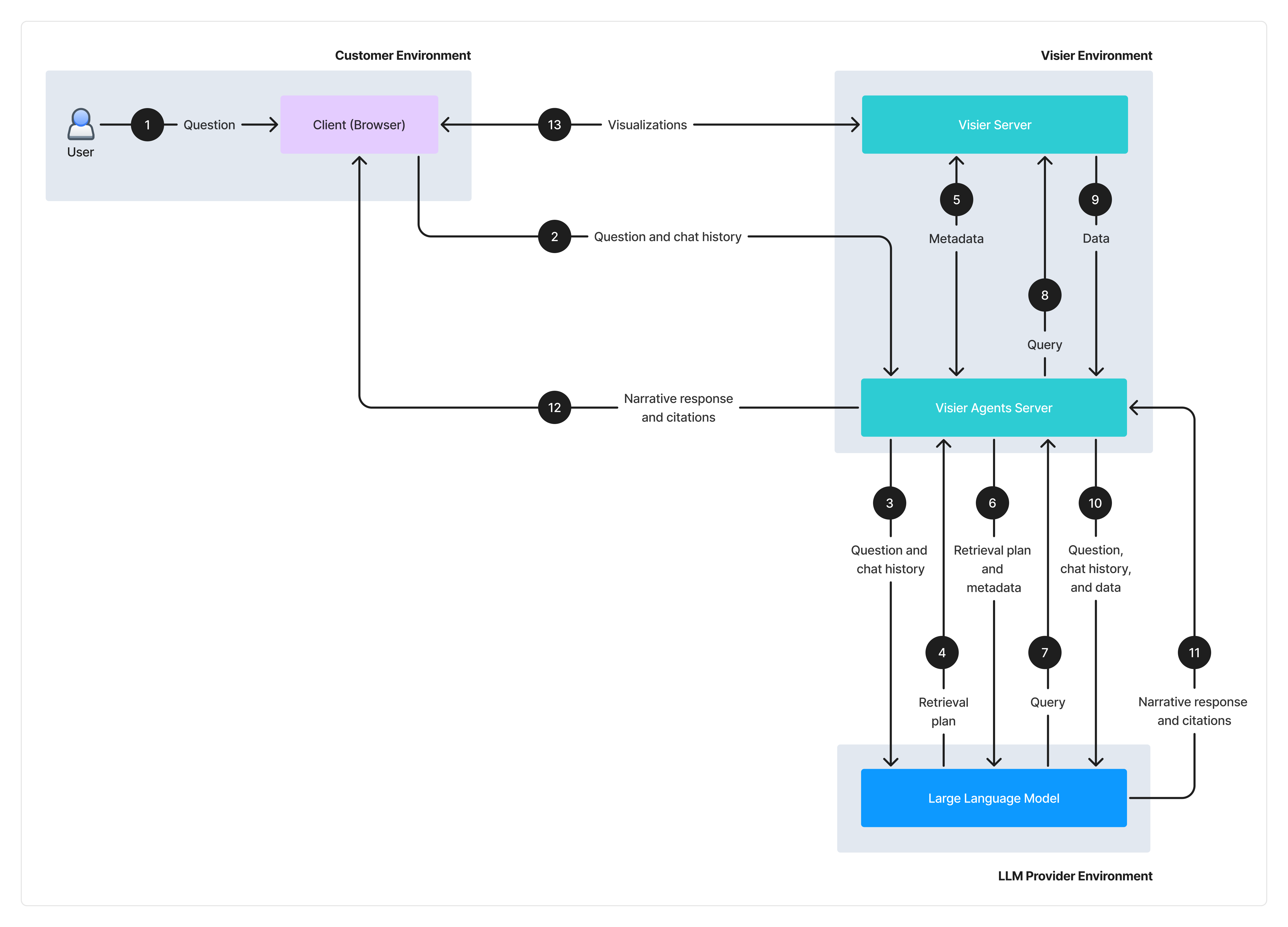
- The user asks a question on the client side in Visier People.
- The client sends the question and any existing chat history to the Visier Agents Server. Both the question and chat history move from the customer environment to Visier’s environment. Chat history is retained in the client when the user interacts through a web browser. Chat history captures previous questions and Vee's responses to provide context for user intent, and may therefore contain customer data.
- The Visier Agents Server sends a prompt containing the user’s question and chat history to the LLM (AWS Bedrock Anthropic Claude or Microsoft Azure OpenAI GPT).
Note: When a user asks Vee to explain a visual or analysis, the client passes additional context, such as the chart or analysis content and metadata, grounding the LLM in exactly what the user sees.
- The LLM generates a data retrieval plan to answer the question. For example, to answer
Do we have a retention problem?, the plan includes steps to retrieve the organization's retention rate and exit reasons for the past 12 months. - The Visier Agents Server retrieves metadata about the tenant schema and user from the Visier Server, which contains the core set of technologies underlying Visier People. Metadata is any relevant information that can be used to produce the best translation of the natural language question such as information about Visier's analytic mode and analytic objects that exist in the tenant.
- The Visier Agents Server sends a prompt containing the data retrieval plan and metadata to the LLM to construct the appropriate query function.
- The LLM generates the queries and returns them to the Visier Agents Server.
- The Visier Agents Server validates the queries before passing them to the Visier Server for execution.
- The Visier Server executes the queries based on the user’s data access and returns the data (metric values) to the Visier Agents Server.
- The Visier Agents Server sends the question, chat history, and retrieved data to the LLM for evaluation. If the LLM determines more data is needed, the sequence loops back to step 3 until sufficient data has been gathered. The LLM then generates a narrative response, summarizing the retrieved data first if necessary to stay within its context window.
- The LLM sends the narrative response and data citations to the Visier Agents Server.
- The Visier Agents Server passes the narrative response and data citations back to the client.
- The client retrieves the referenced visualizations from the Visier Server and renders them for the user.
Ask Vee a question
Vee partners with third-party large language models (LLMs) to help translate and understand the question being asked. The LLM translates the question into a query that Vee uses to generate a response. The following illustration summarizes the architecture and data flow for Vee when a user asks a question.
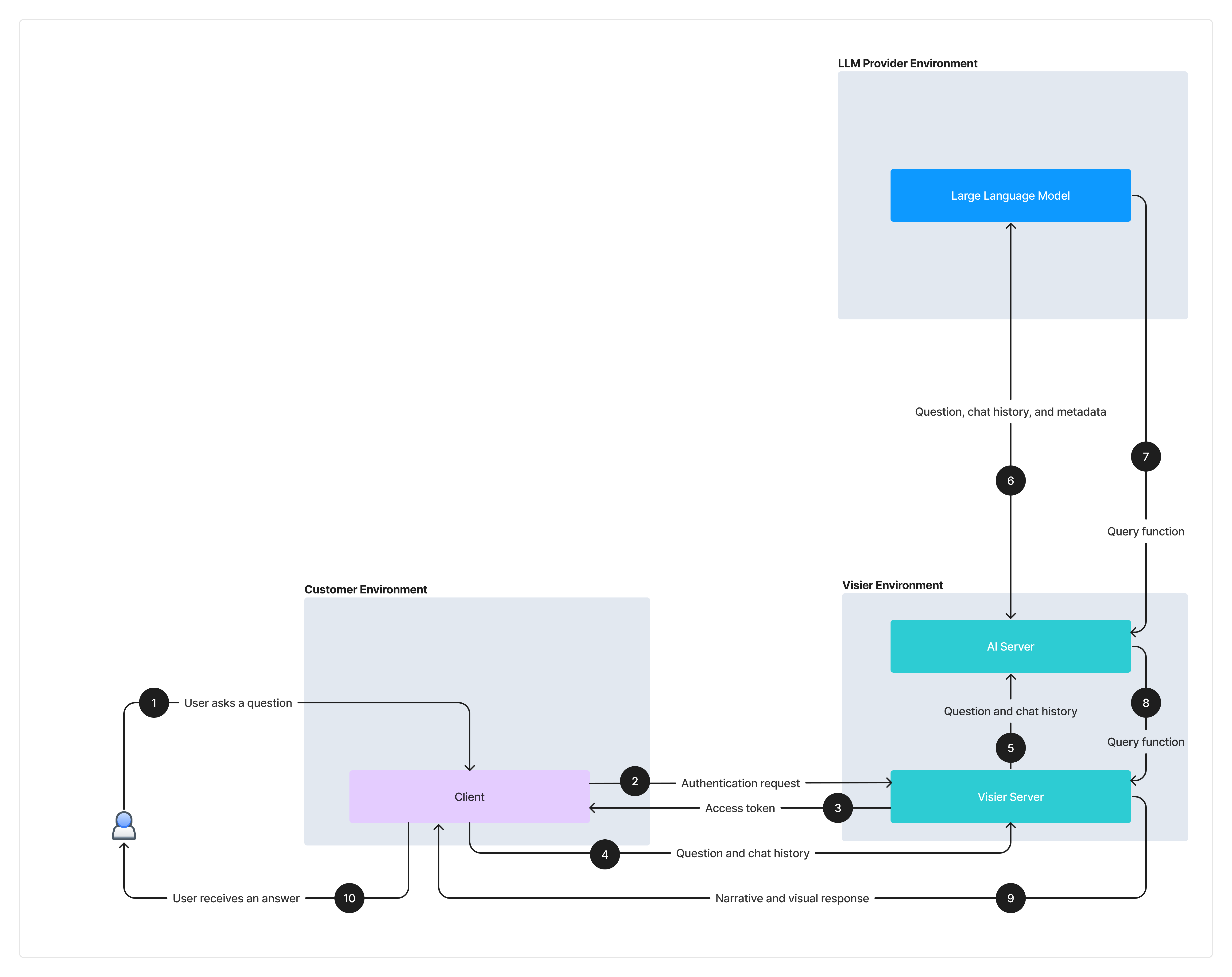
- A user enters a question on the client side in Visier People
- The client makes an authentication request to the Visier server, which contains the core set of technologies underlying Visier People. The Visier server checks the user credentials to verify that the user is valid.
- If the user is valid, the server sends an access token to the client. This allows the client to make additional requests to the Visier server.
- The client sends the question and any existing chat history to the Visier server. Chat history provides context for the user's intent and includes only the user's previous questions, excluding responses from Vee. Both the question and chat history move from the customer environment to Visier’s environment. Chat history is retained in the client when the user interacts through a web browser and in a server-side database for the Microsoft Teams integration. The data stored in the database is encrypted and has a short Time To Live (TTL) of approximately 8 hours.
- The Visier server sends the question and chat history to the AI server. This is where the communication between Vee and large language models (Microsoft Azure OpenAI GPT) occurs.
- In a series of back-and-forth interactions, facilitated by the Azure REST API, the AI server will send the question, chat history, and metadata to the large language models to translate the question into a query that Vee understands. Metadata is any relevant information that can be used to produce the best translation of the natural language question such as information about Visier's analytic model, analytic objects that exist in the tenant, past inferences, and query examples.
- The LLM translates the question into a query function and returns it to the AI server.
- The AI server sends the query function to the Visier server.
-
The Visier server performs the query function and generates a response (narrative and charts) based on the user's data access. The Visier server sends the response data to the client.
Note: For LLM-generated responses, after the Visier server performs the query function, the organizational data retrieved and chat history makes an extra round trip (from the Visier Server > AI Server > LLM > AI Server > Visier Server) before sending the response data to the client. For more information about this feature, see "LLM-generated responses" in What Vee Can Do.
- The user receives an answer back, in natural language, from Vee.
Ask Vee for an explanation
Vee partners with third-party large language models (LLMs) to summarize text. The following illustration summarizes the architecture and data flow for Vee when a user requests an AI explanation in a Vee Board.
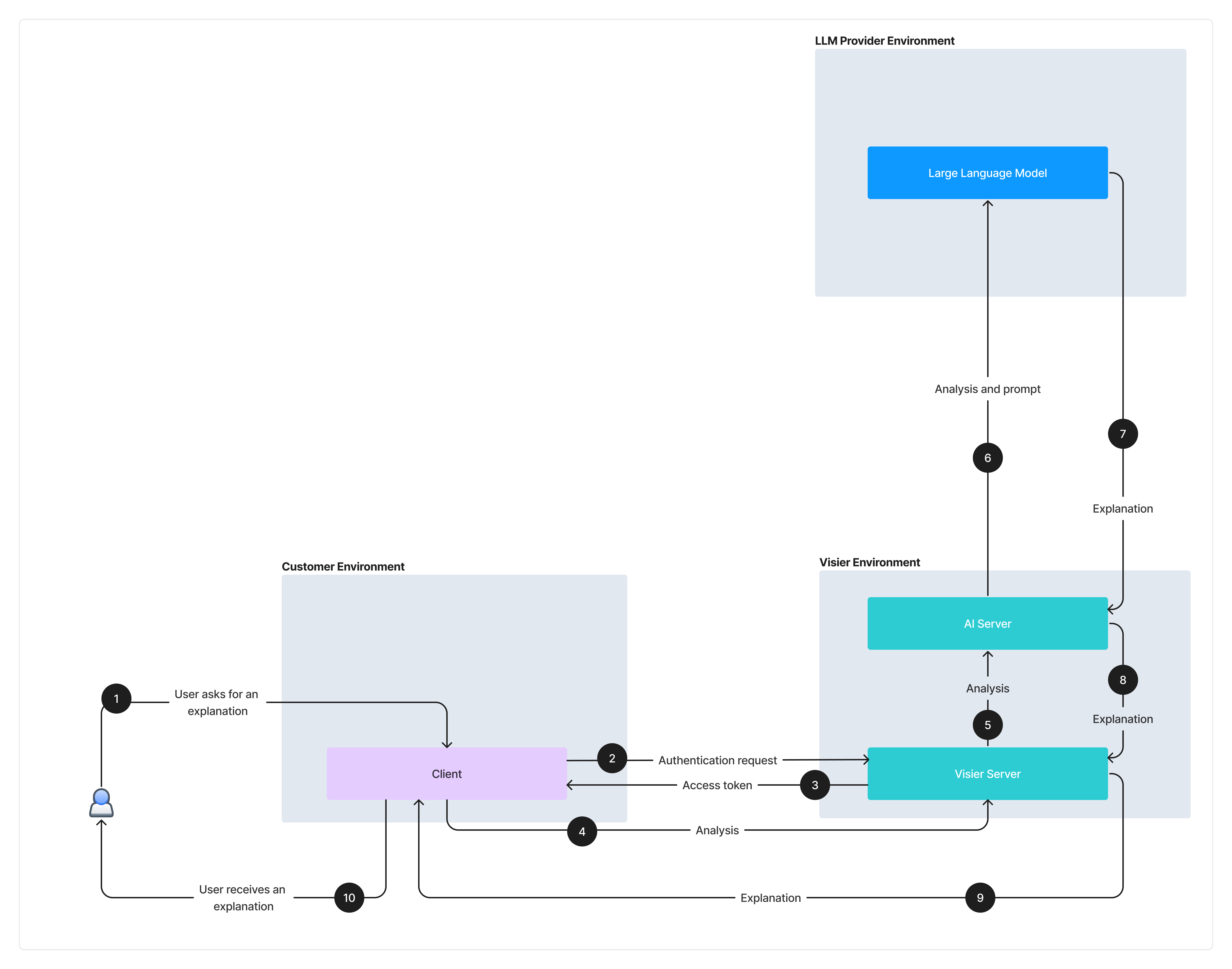
- A user requests an AI explanation in a Vee Board (analysis) on the client side in Visier People.
- The client makes an authentication request to the Visier server, which contains the core set of technologies underlying Visier People. The Visier server checks the user credentials to verify that the user is valid.
- If the user is valid, the server sends an access token to the client. This allows the client to make additional requests to the Visier server.
- The client sends the analysis to the Visier server. The analysis moves from the customer environment to Visier’s environment. The data stored in the database is encrypted and has a short Time To Live (TTL) of approximately 8 hours.
- The Visier server sends the analysis to the AI server. This is where the communication between Vee and large language models (Microsoft Azure OpenAI GPT) occurs. To provide an explanation, the analysis ID, its content, metadata describing the content's structure, and the data within the analysis is sent.
- The AI server sends the analysis along with a prompt to the LLM. The prompt contains instructions that guide the LLM in generating an explanation in natural language.
- The LLM generates an explanation and returns it to the AI server.
- The AI server sends the explanation to the Visier server.
- The Visier server sends the explanation to the client.
- The user receives an AI explanation in a Vee Board.
How Vee is trained
Vee is trained on Visier's analytic model and Blueprint, the complete set of Visier content. Generative AI is only as good as the underlying data it’s trained on. Visier not only brings together all of the disparate data across your HR tech stack, but we also have the content, questions, answers, metrics, and supporting knowledge to understand what the data means and how to explain it to end users. Generative AI makes asking questions easier than ever, and only Visier has the scope of information needed to draw accurate conclusions to nearly any question.
Visier does not train Vee on customer data.
How sensitive data and information is protected
Vee is governed by Visier's trusted data security model. Vee's responses are based on the user's permissions and data access. This means that Vee’s answers from one person to another, while both accurate, will be different.
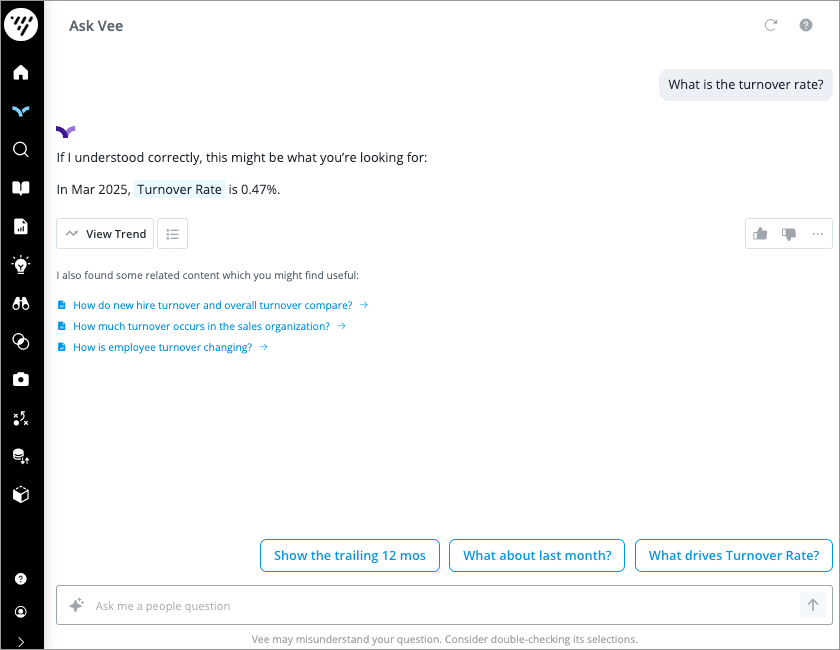
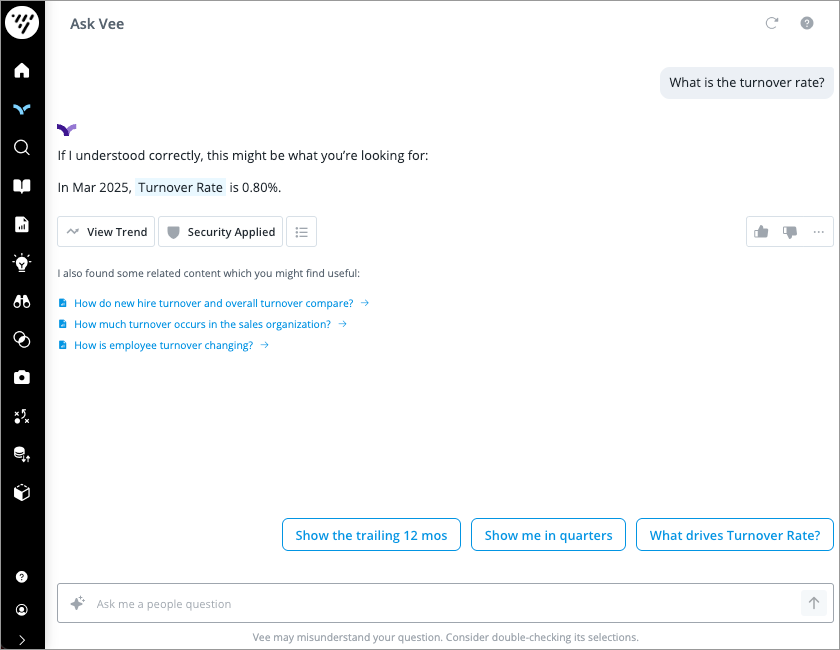
For example, let's look at Vee’s responses to two employees in the same organization who ask the same question, but have different levels of data access. Employee A has full access to all data. Employee B has limited access to data for employees located in the Asia–Pacific (APAC) region.
When Employee A asks Vee What is the turnover rate?, they see a response of 0.47% because that is the rate across all organizational data.
When Employee B asks Vee What is the turnover rate?, they see a response of 0.80% because that is the rate across employees in the APAC region. With the response, they will see the Security Applied shield ![]() , letting them know that their permission restrictions have been applied to Vee’s response. They can click the shield to understand what permission restrictions have been applied as part of security.
, letting them know that their permission restrictions have been applied to Vee’s response. They can click the shield to understand what permission restrictions have been applied as part of security.
AI guardrails
Visier has implemented guardrails to actively protect against prompt injection attacks and harmful content. All questions and prompts are analyzed to detect content that is:
- Malicious: Clearly harmful, unsafe, or inappropriate.
- Unusual: Attempts to manipulate the AI, extract system information, or bypass safety measures.
For Vee and Vee Boards, prompts containing malicious content are blocked. For Text visual summaries, prompts containing malicious or unusual content are blocked.
Approach to responsible AI
Visier builds its AI programs, including Vee, in accordance with the following guiding principles:
- We respect the evolving guidance of legislative authorities globally, including without limitation the Blueprint for an AI Bill of Rights (US), Responsible use of artificial intelligence (AI) (Canada), and the European Commission's proposed EU Regulatory framework for AI (EU).
- We believe in responsible, measured development, over innovation at all costs.
- We ascribe to high levels of transparency, accountability, and explainability.
- We value continued human oversight with appropriate checks and balances on AI autonomy.
- We prioritize data security and limit the sharing and persisting of data.
- We recognize, understand, and address inherent flaws in AI, including the potential for bias, discrimination, and hallucinations.
- We are committed to continuing to learn, to evolve, and to reevaluate with each new development.
Opt out of AI features
Your organization can turn off all AI features that send data to third-party LLMs for natural language processing. Administrators can opt out in Studio by clicking Settings > AI Features in the global workspace.