
Jobs
Jobs define all the tasks needed to load your data into Visier.
The Jobs room
The Jobs room allows you to monitor, trigger, schedule, troubleshoot, and preview data loads that are run within Visier. In the Jobs room, parent jobs and their child jobs are grouped together. Parent jobs and child jobs are the series of jobs that run sequentially to generate a data version. The first job to run is the parent job and the jobs that run after the parent job are children of the parent job. For example, if a receiving job spawned 10 processing jobs and an extraction job spawned 3 processing jobs, the Jobs room will show 2 jobs: the receiving job and the extraction job. You can drill down into those jobs to see more information about their child jobs.
Note:
To access the Jobs room, open a project and click Data > Jobs.
The Jobs room contains the following tabs:
- Status: Review information about your jobs.
- Schedule: Schedule a new job. For more information, see Schedule a Job.
The following table describes what the columns in Jobs or Jobs > Status represent.
| Column | Description |
|---|---|
| Actions | The actions you can perform on the job, such as cancelling or retrying the job. |
| Blueprint Version | The base content upon which the job is based. |
| Child Statuses | The count of succeeded, failed, pending, or running children jobs associated with a parent job. The count is represented as color-coded notes with a number inside to indicate the number of children jobs. |
| Data Origin | Where the data originated from, such as an upload or API request. |
| Data Source Type | The general source of the data, such as customer data. |
| Job Configuration | Denotes if the job is part of the production version or a project. |
| Job ID | The unique identifier of the job. |
| Job Source | Indicates how the job was initiated. There are two job sources:
|
| Job Type | The type of job that was triggered.
|
| Parent ID | Present for processing jobs. Several processing jobs can share a Parent ID. Since the batch file contains data for multiple analytic tenants, the Parent ID is typically the related receiving job ID. |
| Progress | Indicates the progress and duration of a job for its current stage. If Auto Refresh is enabled, the progress bar updates every 10 seconds. You can also click Refresh to see the progress of the job in real time. |
| Stage | Indicates the current phase of a running job or the stage where a job failed. To see the progress of a job through the stages, select a job. |
| Start Time | The date and time when the job was initiated. |
| Status | Indicates the current state of the job, such as Running. |
| Tenant Code | The unique identifier of the tenant that the job is associated with. |
| Tenant Name | The name that's shown for the administrating tenant or analytic tenant for which the job was run. |
Job statuses
Each job has a status that indicates its current state. The following table defines each job status.
| Job status | Definition |
|---|---|
| Pending | The job is waiting for computing resources. |
| Running | The platform is performing the job's task, such as creating a data version or retrieving data from external data providers. |
| Succeeded | The platform finished its task successfully. |
| Failed | The job failed to complete. |
| Cancelling | The job is in the process of getting canceled. It may or may not generate a data version, depending on its current stage. |
| Cancelled | The job was canceled and no data version was generated. |
| Scheduled | The job will run later. |
| Rescheduling | The job is in the process of getting after an issue with the job caused it to fail. |
| Rescheduling Requested | The job reschedule was requested. |
| Rescheduled | The job reschedule was requested successfully. |
Reorganize the jobs list
Use the filter, search, and sort features to show the jobs that are most important to you.
When you have many tenants and data version jobs, the jobs list can get long. You can filter and sort the jobs or reorder the columns.
Filter the jobs list
Filters are provided to narrow the jobs list to some particular focus or criteria. You can filter by time, job type, job configuration, child job status, job status, and job level. When finished selecting your filters, click Apply.
- Search: Select whether to search by tenant code or job ID. This option is available to administrating tenants.
- Time: Narrow down the relative start time to focus on jobs that were run during a specific time period.
- Job Type: Allows you to filter by Job Type. This is a quick way to determine how each job ran.
- Job Configuration: A multi-select filter that lets you determine which environment (production or project) that jobs were run against and the state of the data version deployment.
- Child Status: Filter on the status of the child jobs. Child jobs are jobs that were spawned from a parent job. For example, a receiving job might spawn several processing jobs. In this example, the processing jobs are child jobs. The color and number in the Child Statuses column indicates the following:
- Green: The number of succeeded child jobs.
- Red: The number of failed child jobs.
- Gray: The number of pending child jobs.
- Blue: The number of running child jobs.
- Status: Filter on the different job statuses; for example, only failed jobs. All completed jobs are shown as Complete, including Succeeded and Failed jobs. Similarly, Incomplete shows all jobs that are Pending or Running.
- Job Level: View the entire list of jobs or only the top level jobs. Top level jobs are jobs that have no visible parent, that is, the job wasn’t spawned by another job that you can see. For example, a receiving job might spawn several processing jobs. In this example, the receiving job is the top level job. This option is available to administrating tenants.
Search the jobs list
You can search for jobs by Job ID or Parent ID.
To search for a Job ID, click the Job ID to copy the ID to the clipboard and then paste it into the Search Jobs field, as shown next.
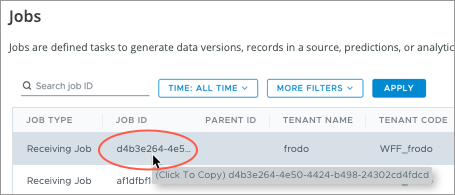
Filter and search together
The search and filter features can be used in combination. For example, you can narrow the list to succeeded jobs initiated in the last seven days for a specific tenant.
By default, jobs are sorted in descending order based on Start Time; that is, most recent first, as shown next.
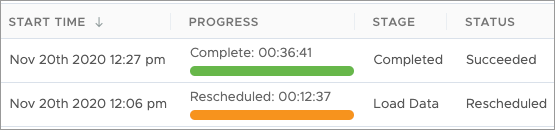
Users have the option to sort based on Job Type, Parent ID, Tenant Name, Tenant Code, Job Config, Start Time, Status, and Job Source.
For example, clicking the Status column header allows you to see jobs listed by the job status, as shown next.
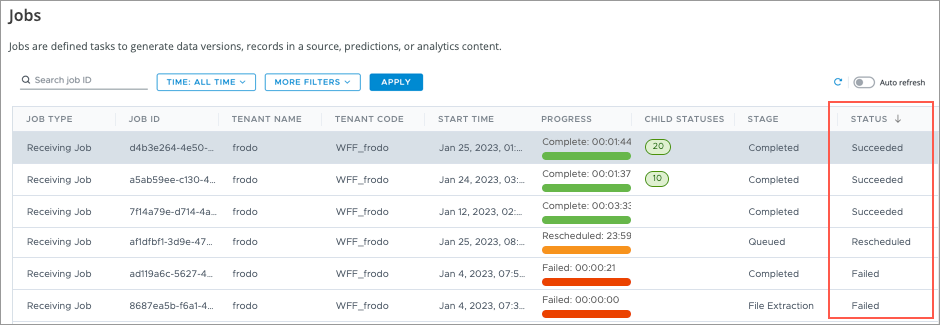
Clicking the column header again shows the results in descending order.
Note: You can only sort on one column at a time.
Reorder the jobs list columns
The default order of columns may not be your preferred order.
To reorder the columns, click a column header and drag it to a new location.
Drill down on a job
Clicking a job in the Jobs room navigates to the job page, which provides detailed information about the specified job.
The following screenshot illustrates the job page for a completed receiving job.
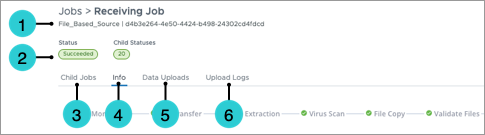
- Job Name and Job ID: The name of the job, such as the main data load, and the job's unique ID.
- Status and Child Statuses: The status of the job and the count of succeeded, failed, pending, or running child jobs.
- Child Jobs: If the job spawned additional jobs, this tab lists the spawned child jobs.
- Info: Additional information about the job, such as the status of the job stages, the job type, start time, status, and uploaded ZIPs.
- One of:
- Data Uploads: For receiving jobs, the tenants that have new data as a result of this job. You can include or exclude the data associated with this job for the tenants.
- File Validation: For processing jobs and extraction jobs, additional information about the data files in this job, such as any errors or data version information.
- Debug Inspector, Processing Issues, Troubleshooting Viewer: For extraction jobs, you can validate whether there were issues with the job using the debug inspector and other validation tools.
- Upload Logs: Any issues or errors associated with the files in this job.
The following screenshot illustrates the job page for a canceled processing job.
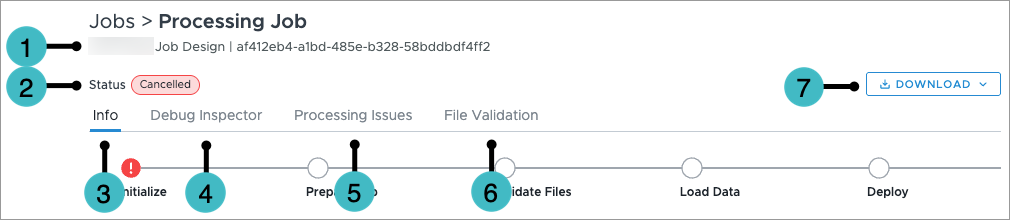
- Job Name and Job ID: The name of the job, such as the main data load, and the job's unique ID.
- Status: The status of the job.
- Info: Additional information about the job, such as the status of the job stages, the job type, start time, status, and uploaded ZIPs.
- Debug Inspector: Information related to at least one subject attribute, such as Employee ID or Organization Hierarchy ID. For more information, see Debug Inspector.
- Processing Issues: Describes the issues in a failed processing job and lists the error's RCI code, the job stage that the error occurred, and, if applicable, the data file, line, and subject ID associated with the error. You can search within the table for specific issues, such as by RCI code or subject ID.
- File Validation: Additional information about the data files in this job, such as any errors or data version information.
- Download: Options to download the job log and processing issues.
- Job log: Contains event statements that occurred during the job in LOG format. For more information, see Jobs.
- Processing issues: Contains the same information as the processing issues table in CSV format. For more information, see Download processing issues.
To navigate back to the Jobs room, click Jobs, as shown next.

You can also navigate back to a previous job in the hierarchy, such as from a child job to a parent job, by clicking the previous job in the navigation path. For example, to navigate from a receiving job to its parent extraction job, click Extraction Job, as shown next.

Below the header is a visualization of the job stages. A stage may have one of the following icons:
| Icon | Description |
|---|---|
|
|
The stage was not executed. |

|
The stage has successfully completed. |
|
|
The stage has failed. |
Download a job log
Access requirements
Custom profile with these capabilities: Data (Read, Simple) and Manage Jobs
Reach out to your administrator for access.
In the job's details page, you can download a job log to learn more about the job. Job logs provide more information about the job, such as subject IDs to investigate or failed value conversions.
Note:
- Job logs are downloadable within Amazon WorkSpaces (AWS).
- Job logs do not contain records from source files; no sensitive data is included.
- You can download a log up to seven days after the job ran. If you try to download a job that ran more than seven days ago, you'll see an error message.
To download a job log:
- Open a project.
- On the navigation bar, click Data > Jobs.
- Click a completed job to open the job details page.
- Click Download > Job logs.
The following table describes the information included in a job log.
| Field | Description |
|---|---|
| Date | The date that the log value is valid in yyyy-MM-dd HH:mm:ss,SSS format. |
| Type |
Whether the log value is INFO, WARN, or ERROR.
|
| TenantCode | The unique code associated with the tenant in which the job ran. |
| JobId | The unique identifier of the job. |
| Task | The task associated with each log value. For example, running file validation or excluding files. |
Download processing issues
In a failed processing job's details page, you can download its processing issues in CSV format. The CSV file contains the same details as the processing issues table in the job's Processing Issues tab. Processing issues provide more information about the job failure, such as missing source files or unmapped properties.
To download a job's processing issues:
- Open a project.
- On the navigation bar, click Data > Jobs.
- Click a failed processing job to open the job details page.
- Click Download > Processing issues.
The following table describes the information included in the processing issues CSV file.
| Field | Description |
|---|---|
| Severity |
Whether the issue is INFO, WARN, or ERROR.
|
| Substage |
The event stream stage in which the error occurred, such as normalizer or business rules. For more information, see Main event stream stages. |
| RCI | A root cause identifier that allows Visier to determine the source of the problem. If you are unable to troubleshoot the issue, provide the RCI to Visier Technical Support for assistance. |
| File | The data file associated with the issue. Empty if no file is relevant. |
| Line | The data file row associated with the issue. Empty if no file is relevant. |
|
ID |
The unique identifier of the subject associated with the error. Empty if no subject is relevant. |
|
Message |
The details of the error. |
Receiving job stages
A parent receiving job triggers one or more child receiving jobs, each of which trigger processing jobs. This enables validation to occur at the child level, rather than validating all files at the top-level, which improves overall job performance.
The stages of a parent receiving job are described as follows:
| Stage | Description |
|---|---|
| File Monitoring | Monitors the received data files to ensure receiving is complete before continuing. |
| File Transfer | Transfer the data files to the extraction folder. |
| File Extraction | Decrypts and extracts the received data files into a temporary extraction directory. |
| Virus Scan | Scans the extracted files for viruses. |
| File Copy | Copies the extracted files from the temporary extraction directory into a tenant data folder. |
| Spawn Jobs | Schedules receiving jobs for the analytic tenants with data in the payload. |
| Cleanup | Cleans up temporary files. |
The stages of a child receiving job are described as follows:
| Stage | Description |
|---|---|
| Excel Extraction | Extracts values from an Excel file to Visier. |
| File Validation | Validates the schema associated with the file, such as the encoding and delimiter. |
| Source Generation | Creates a source in Visier for the source file, or connects the source file to an existing source in Visier. |
| Preprocessing | Prepares the file for processing. |
| Record Validation | Validates the records associated with the file. |
| Tenant File Update | Updates the tenant files with values from the receiving job. |
| Processing Pipeline | Processes the file in the data pipeline. In this stage, the platform checks whether skipDataLoad is true or false. If false, the job runs. |
| Profile Generation | Generates a profile for the file in Visier. |
| Update Parent Job Properties | Updates the properties associated with the parent job of the receiving job. |
| Cleanup | Cleans up temporary files. |
Processing job stages
The stages of a processing job are described as follows:
| Stage | Description |
|---|---|
| Initialize | Begins the processing job. |
| Prepare Job | Prepares the job to run. |
| Validate Files | Validates the files associated with the job, including schema validation and record validation. |
| Load Data | Loads the data values from the files into Visier. |
| Deploy | Deploys the data to the production version of the solution. |
| Cleanup | Cleans up temporary files. |
In this section