
Load Data Using a Data Warehouse Connector
Learn how to extract employee data from your source system and load it into Visier using a data warehouse data connector.
Introduction
Visier's data connectors simplify the data loading process. Using an automated workflow, data connectors connect and extract the raw data directly from your source systems, subsequently transforming and processing it within the Visier platform.
Visier seamlessly connects to multiple data sources using the different connector types below.
-
Human capital management (HCM) data connector: Connects to Human Resources Information Systems (HRIS) and Applicant Tracking Systems (ATS) with a fixed data model. Leverages templates to load data into Visier.
-
Data warehouse data connector: Connects to generic data warehouses/databases that hold any data type. Requires some manual configuration to load data into Visier.
In this tutorial, you will learn how to load employee data for the first time into Visier using a data warehouse data connector. For a list of data sources compatible with this connector, see below.
-
Amazon Redshift
-
Google BigQuery
-
Microsoft SQL Server
-
MySQL
-
Oracle Database
-
Snowflake
To learn more about the data sources we support, see Data In Connectors for more information.
Objectives
We will first walk you through the connector setup and configuration, and then show you how to run a data extraction job to retrieve the data from your source system. After the data has been retrieved and sources are created, we will show you how to create mappings for each source. This will connect the source files' columns to the analytic objects' properties in Visier's analytic model. We will then show you how to run a job to generate a data version.
By the end of this tutorial, you will have extracted data from your data source and loaded it in your Visier solution.
In our example, we will be loading data from Amazon Redshift so we can analyze employee starts and exits in Visier.
You will learn how to:
- Setup connector credentials
- Create a data connector
- Run a data extraction job to retrieve data from your source system
- Create and configure mappings to specify how data in your source is loaded into Visier
- Run a job to generate a data version
- Preview the data in the solution
Prerequisites
Before beginning this tutorial, you will need:
- A Visier account that has the following profiles. If you don't have an account, contact your administrator.
Data Engineer
-
A Visier account with a permission that allows the user to access guidebooks, analyses, the Explore room, and data access to view the data you’re loading. For more information, see Data and Content Security.
- Ad Hoc Analysis
- Create Analysis Context
- Change Analysis Context
- Guidebook
- View Details
Steps
Set up a service account in the source system
To start using Visier's data connectors, we first need to create a service account in our source system. This is an important step as it enables Visier to connect to our source data.
When creating a service account it's recommended to use an integration user for integration with third-party systems like Visier.
Please refer to your source system's documentation to create an integration user and provide the integration user with all the required permissions to perform integration actions. Depending on the source system, the required permissions may be different. For more information, see Supported connectors and requirements.
In this tutorial, our source system is Amazon Redshift.
Create a project
Next, sign in to Visier. After you sign in to Visier, you are directed to the solution experience or Studio. This is dependent on capabilities, permissions, and if you've previously loaded data into Visier. If you start in the solution experience, on the navigation bar, click Studio ![]() , where we can create a project.
, where we can create a project.
Next, we need to create a project in Studio to hold our work. Projects are how Visier handles version control, allowing you to define and edit the solution separately from the current production version of the solution. For more information, see Use Projects for Version Control.
- On the global navigation bar, click Projects.
- In the Projects room, click New Project.
- In the New Project dialog, type a name and description for the project. We can name our project Visier Tutorial with a description of Load, configure, and publish essential Employee data.
- Click Create.
Result: The project home appears.
Provide connector credentials in Visier
After our service account has been created in Amazon Redshift and we have a project in Visier, the next step is to connect it to Visier by creating a set of connector credentials.
The connector credentials are used to authenticate Visier with our source system and are created within Studio, which serves as the administrative design space. To learn more about Studio, see Navigate Studio.
- In your project, on the navigation bar, click Data > Connectors.
- Click Create Connectors.
- In Select Credential, click Add new.
- Type a display name and description. We can name our connector credential Amazon Redshift with a description of Tutorial sample data.
- Click Next.
- In the list of connectors, select Amazon Redshift, and then click Next.
- Type the requested information:
- Endpoint
- Port
- Database
- Username
- Password
Note: The required credentials differ by source system. For more information, see Supported connectors and requirements.
- To ensure the credentials work as intended, click Authenticate.
- Once the authentication is successful, click Next.
Create a connector
In the same dialog that we provided connector credentials, we can create the connector to extract data from our source system.
- In Basic Information, type a display name and description for the connector. In this tutorial, we can name the connector Tutorial Sample Data with a description of Essential employee data.
- Click Create.
Create a data category
Now that we've created the connector, we need to create a data category for our data.
A data category represents a dataset loaded into Visier that runs on a unique data load frequency. Each data category has its own set of instructions to generate a data version. A data version is a instance of uploaded data with a unique release number. For more information, see Data Versions.
The "instructions" within a data category bring together the mappings from source data to objects in Visier's analytic model.
- In the project, on the navigation bar, click Data > Data Categories.
- Click Create Data Category.
- In the Create data category dialog, type a display name and description. We can name our data category Visier Tutorial Data with a description of Instructions to load data for tutorial.
- Click Create.
Result: The data category is created.
After a new data category is created, Visier generates a new tenant setting, Tenant_Design_0, and automatically assigns it to the data category. Tenant settings define information about the tenant, including the data start and end dates. This tenant setting should be automatically assigned to the data category.
Check that the tenant setting is assigned to the data category:
- In the data category, click the Settings tab.
- Under Tenant setting, ensure Tenant_Design_0 is selected.
Note: Start date prior to 12/31/2004
By default, the start date for Tenant_Design_0 is 12/31/2004. If the data you're loading has a start date prior to 12/31/2004, you must update the start date in the tenant setting. If you're using the sample files, you can skip this step because the sample data does not contain a start date prior to 12/31/2004.
Update tenant start date:
- In the project, on the navigation bar, click Data > Tenant Settings.
- Select the auto-generated tenant setting, Tenant_Design_0.
- In the Settings tab, under Start date explicit date, type or select the start date for your data. For more information, see Tenant Settings.
Determine what data we want to extract
After the connector has been created, we need to determine what data we want to extract from our source system by selecting from the list of imported tables.
Each table represents an analytic object in Visier's analytic model, such as Employee or Compensation.
For our first data extraction it is recommended to include a subset of core data to start with, such as employee, employee start, and employee exit. This approach keeps data load times at a minimum.
- In the Customize tab of the connector, click Select Tables.
- In the Select tables to include for extraction dialog, select the data you want to extract from the Imported Tables list. In this tutorial, we are selecting public employee, public employee_exit, public employment_start, and public organization_hierarchy tables.
Note: Table names differ by source system.
- Click Done.
Run a data connector extraction job
Once we've selected the data from the imported tables list, it's time to extract the data from our source system by running a data extraction job. Jobs define the tasks needed to load your data into Visier, for more information, see Jobs.
After the data extraction job is complete, the data is loaded into Visier as sources. Sources store data for your solution, for example, Employee data is stored in the Employee source. For more information, see Sources.
- In the connector, click Schedule Job > Custom.
- In the Schedule job dialog, in Advanced, turn off Generate objects. The only options that should be enabled are Run now and Extract data. We do not need to turn on the Process data option because we're just extracting data from the source system. We will process the data and generate a new data version in a later step.
- In Connectors, make sure that Amazon Redshift Connector is selected. In this tutorial, we named the connector Tutorial Sample Data.
- Click Schedule.
Result: The job begins immediately. To see the job's progress, navigate to Data > Jobs on the navigation bar.
In this tutorial, the job automatically generates the following sources:
- Public_Employee_GH
- Public_Employment _Start_GH
- Public_Employee_Exit_GH
- Public_Organization_Hierarchy_GH
We can check our sources to verify the data was extracted correctly.
- To go back to the global workspace, on the navigation bar, click Back to Projects.
- On the global navigation bar, click Data > Sources.
- Select a source and click the Uploaded Files tab.
- Check the latest uploaded file and confirm that the number of records is correct in the Records column. There should only be one file for each source as this is the first time we have loaded this data.
The following table describes the number of records for each file.
|
Source |
File |
Number of Records |
|---|---|---|
|
Public_Employee_GH |
Public_Employee_GH*.txt |
10956 |
|
Public_Employment _Start_GH |
Public_Employment _Start_GH*.txt |
649 |
|
Public_Employee_Exit_GH |
Public_Employee_Exit_GH*.txt |
260 |
|
Public_Organization_Hierarchy_GH |
Public_Organization_Hierarchy_GH*.txt |
628 |
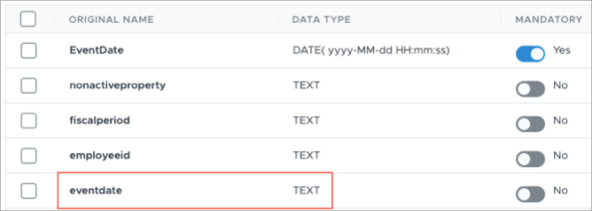
We can also check the Columns tab to ensure all the expected columns have been loaded and that each column has the correct data type. In this tutorial, we want to look at the columns to familiarize ourselves with the sample data.
When inspecting the columns for the sources, you may notice two event date columns: EventDate and eventdate. The EventDate column is automatically generated because every file requires an event date. While, the eventdate column is where the actual event dates are stored the source system. However, the data type for the eventdate column is set to Text, which is incorrect. When we do our mappings, we will have to ensure the correct event date source column is selected and the correct data type is used.
Now that you've loaded data, we will show you how to create mappings for each source. This will connect the source files' columns to the properties in Visier’s analytic objects. We will then show you how to run a job to generate a data version.
Create mappings
Next, we need to create mappings for each of our sources. Mappings connect the source files' columns to the properties in Visier’s analytic objects. For more information, see Mappings.
Let’s start with our employee data and create a mapping for our employee source.
To create a mapping:
- In the project, on the navigation bar, click Data > Mappings.
- Click Create Mapping.
- In the Create mapping dialog, select the data category you created. In this tutorial, we named our data category, Visier Tutorial Data.
- In Mapping type, select the appropriate mapping type. In this tutorial, we will select Regular for all the mappings. For more information about mapping types, see Add a Mapping.
- Type a display name and a description for the mapping. We can name our mapping Employee Mapping with a description of Data extraction rules for the employee analytic object.
- Select the source and its corresponding data load target. Because we're starting with our employee data, we will select Public_Employee_GH as our source and Employee as our data load target. The following table describes which data load target we will be selecting in this tutorial.
Source
Data Load Target
Public_Employee_GH
Employee
Public_Employment _Start_GH
Employment_Start
Public_Employee_Exit_GH
Employee_Exit
Public_Organization_Hierarchy_GH
Organization_Hierarchy
- In Data type, select the correct data type for the source. In this tutorial, our employee data is Transactional profile. The following table describes which data type we will be selecting in this tutorial.
Source
Data Type
Public_Employee_GH
Transactional profile
Public_Employment _Start_GH
Conception event
Public_Employee_Exit_GH
Termination event
Public_Organization_Hierarchy_GH
Transactional profile
Note: The data type is dependent on how the source data is formatted. For more information about mapping data types, see Add a Mapping.
- In Override behavior, select the correct override behavior for the mapping. The override behavior defines how the loader uses newer records to overwrite older records. For more information, see Add a Mapping. In this tutorial, we will use the default override behavior for each mapping.
- Click Create.
Result: The mapping is created.
After we create mappings for the rest of our sources, it's time to configure each mapping.
Configure mappings
Once we have created our mappings, we need to map the source columns to the analytic object properties. This can be done by utilizing the automap feature which streamlines the mapping process through string matching.
Let's start with our employee mapping.
- In Mappings, select the mapping that you want to configure.
-
In the mapping, click Automap
 .
.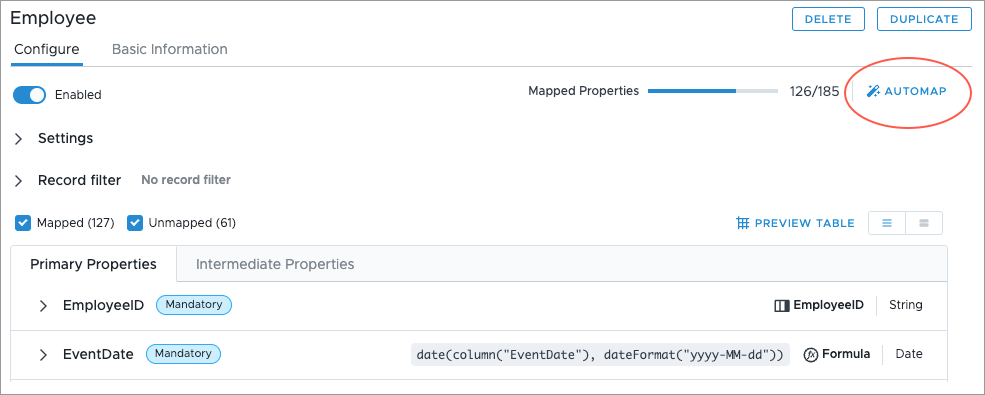
Result: The properties with matching source columns are mapped.
- In Properties, check the mapped items to ensure all your source columns were correctly mapped to a property. A property is mapped correctly if it shows the correct source column name or formula. For example, EmployeeID is mapped to the EmployeeID column and not the Birth_Date column. You can preview the records in the mapping by clicking Preview.
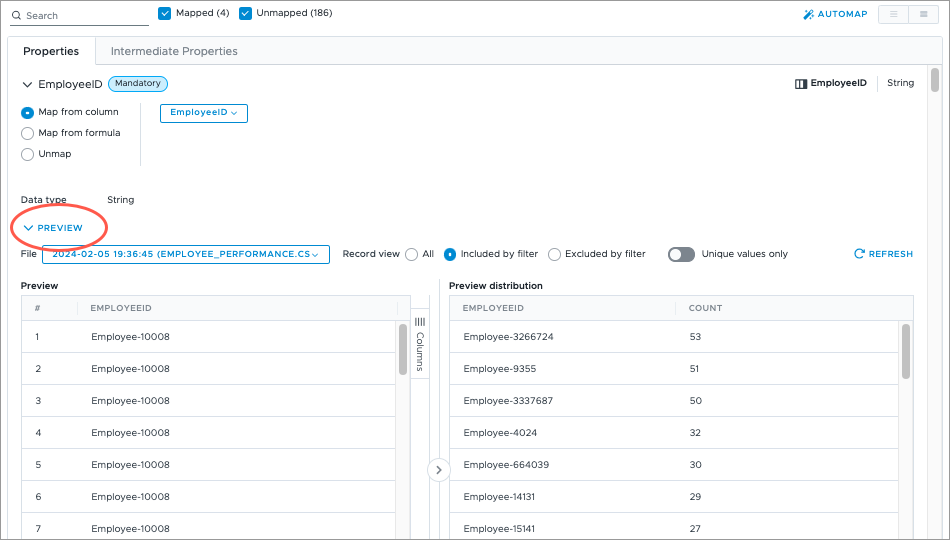
- As noted earlier, our source contains two event date columns. We will have to check that the EventDate mandatory property is mapped to the correct source column after we automap. For more information, see Change EventDate property mapping.
Once we're satisfied with our employee mapping, we will have to configure the rest of the mappings to map the source columns to the analytic object properties.
Change EventDate property mapping
The EventDate mandatory property must be mapped to a source column with the correct data type that includes a date format.
In this tutorial, when we automap, the auto generated EventDate column is selected as the source column. This is incorrect as we want the property to be mapped to the source column where the actual event dates are stored in the source system (eventdate). Additionally, the eventdate column is set to the wrong data type (Text). We need to change the data type so our event dates are converted from a string to a date. Therefore, we have to manually change the EventDate property mapping to use the correct source column and data type.
To change the EventDate property mapping:
- In the Configure tab, expand the EventDate property.
- Change the mapping from Map from column to Map from formula.
- Enter the formula date(column("eventdate"),dateFormat("yyyy-MM-dd")) and click Validate. The formula selects the eventdate column from the source and the data is converted to the specified date format.
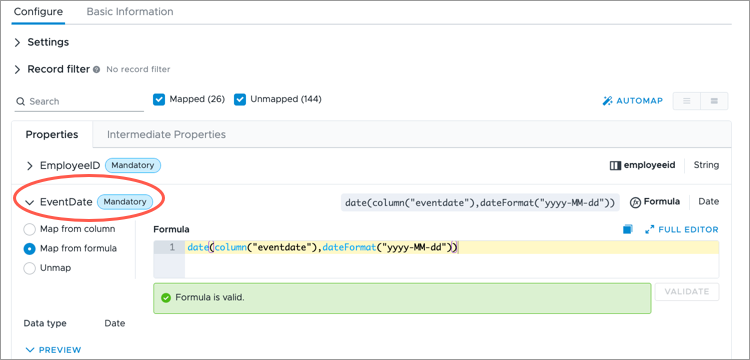
- If successful, when previewing the mapping, the event date for each record will be displayed in the full date time format as shown in the following illustration.
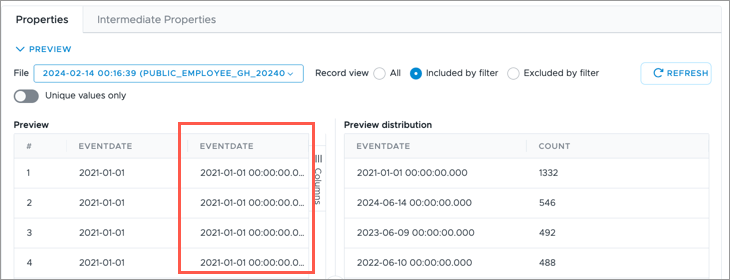
In this tutorial, you will have to manually change the EventDate property mapping for each mapping we created.
(Optional) Add business rule
In this tutorial, our employee data is transactional. To correctly use this data in Visier, we need to create a business rule that create profiles from transactions for the Employee subject, which will ensure the headcount is correct when we validate the data.
Note: What is transactional data?
Transactional profile is a hybrid of temporal and transactional log types. The data excludes any unchanged records and includes each changed record in its entirety. The data is wide, where each row is included if one or more attributes have changed. The time associated with the change is included in the record.
Transactional data, both log and profile types, are less verbose than temporal data and require more data business rules to create system events. To determine what type of data you’re loading, see Add a Mapping.
To add a business rule:
- In the project, on the navigation bar, click Data > Rules.
- In the Business Rules tab, click Create Rule.
- In the Create rule dialog, in Data category, select the data category you created. In this tutorial, we named our data category, Visier Tutorial Data.
- In Rule type, select Business rule.
- Type a display name. We can name our business rule Employee Conception and Termination Rule.
- Select the subject for the business rule. In this tutorial, we are selecting Employee as the subject of the business rule.
- Type a description. For example, Create profile conceptions and terminations based on events.
- In Formula, type call call createProfilesForCTEvents(). This generates profile conception and termination events from actual conception and termination events.
- Click Create.
Result: The business rule is created.
- In the business rule we created, in the Configure tab, click Validate.
Run job to generate a data version
Once we've created and configured our mappings, it's time to run a job from our data category to generate a new data version, this will allow us to preview the data in the solution.
- In the project, on the navigation bar, click Data > Data Categories.
- On the data category we created for our data, in the Actions column, click the More button
 . In this tutorial, we named our data category, Visier Tutorial Data.
. In this tutorial, we named our data category, Visier Tutorial Data. - Click Run job.
- In the Configure Data Loader dialog, click Run job. In this tutorial, we'll use the default job settings.
To check the status of the job, navigate to Data > Jobs.
- In the Status tab, click Refresh. The job should now appear in the list.
If successful, a release number appears in the Data Version column. This means a data version is generated and the job is complete.
Set the data version
If the data version release behavior is set to manual release or custom release, you will have to change the data version of your project in order to preview the new data version.
To set the data version:
- In a project, on the navigation bar, click Data > Data Categories. For more information, see Set the Data Version.
Check that data is available in the solution
Note: If you open the solution experience and can’t access any analyses or the Explore room, you may not have the correct permission capabilities. For more information, see Data and Content Security.
Now that we've generated a data version, we need to confirm that data has been loaded and appears in the solution. At this point, we are not concerned about the accuracy of the values that we see in the solution because we still need to set up the analytic model for the metrics to work correctly. In the next tutorial, we will configure concepts and validate our data.
To preview the solution:
- In the project, on the navigation bar, click Preview Solution.
Result: A preview version of the solution opens in a new tab.
We will use the Explore room to check that data has been loaded. The Explore room is where you can conduct most of your ad hoc analysis in the solution and customize visuals to suit your needs.
To navigate to the Explore room, click Explore ![]() on the navigation bar.
on the navigation bar.
Use the various elements to analyze your data and build a visual to suit your needs.
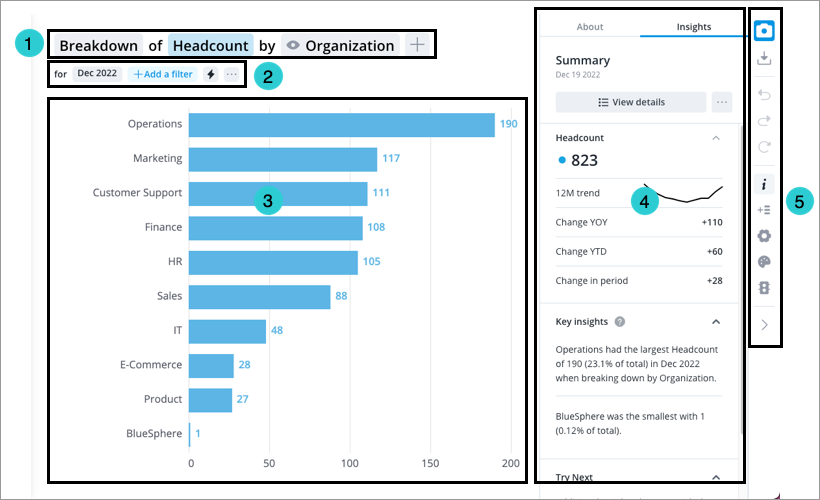
- Visual title: Describes and controls the data that is displayed in the chart. Click the Metric picker, Visual picker, and Group By picker in the visual title to change the data that is displayed. For more information, see The Visual Title.
- Analysis Context toolbar: Change the Analysis Context to select the population and time period for analysis. For more information, see The Analysis Context.
- Chart: Graphical representation of one or more metric.
- Side panel: View contextual information about selected metrics and data points, customize the appearance of your chart, and change chart configurations.
- Visual Actions menu: Use these quick access buttons to perform chart actions and open chart customization and configuration options in the Side panel. For more information, see Visual Actions Menu.
To build a visualization and check data in the Explore room:
- In the visual title, click the Visual picker and select the Breakdown visual.
- In the visual title, click the Metric picker and select a metric. In this tutorial, let's select the Headcount metric.
- In the visual title, click the Group By picker and select an attribute to organize the data. In this tutorial, let's select Organization.
- Check that the visualization loads and you values appear for your groupings.
- In the analysis context, click the Time picker. Click to change the granularity, time period, and time window to ensure data has been loaded for the time periods that your source data covers.
If our visualizations load and we see values, then we have successfully loaded data into Visier.
Commit project changes
Now that we’ve confirmed that data has been loaded, it’s a good time to commit our changes. Committing changes acts as a save point for your project.
- In the project, on the navigation bar, click the Home button
 .
. - Click the Changes tab in the project home.
- Click Commit All.
- In the Commit Changes to Project Revision dialog, type a name and description for the project revision. We can name our revision Initial Data Load with a description of Generated data version.
- Click Commit now.
Next steps
Now you know how to load data into Visier using a data warehouse data connector! This tutorial walked you through how to set up, create and run the tasks needed to extract the data from your source system.
After loading data, you will learn how to configure concepts to connect your data values to Visier’s analytic model.
In the next tutorial, you will learn how to configure concepts to connect your data values to Visier’s analytic model. For more information, see Configure Concepts After Loading New Data.